



#23 : Comment j'ai réussi à gagner des abonnés de manière automatisée ? (Part 1)
L'automatisation LinkedIn qui fait grandir votre audience, sans effort.


Introduction
Hello 👋
La barre des 1 000 abonnés est franchie ! 🥳 Merci d’être là, scénario après scénario.
Pour célébrer cette Milestone, je vous partage un scénario spécial : l’automatisation LinkedIn qui a boosté cette newsletter comme jamais.
C’est un scénario puissant mais dense. Pour que ce soit clair et actionnable, je l’ai découpé en deux parties. Voici la première, et la suite arrive dans quelques jours. 🚀
Prêt à automatiser ? Let’s go.
🙏 Envie de me soutenir ?
Crée un compte Make avec ce lien affilié (tu auras 1 mois gratuit)
Prends rendez-vous avec moi pour discuter automatisation
Propose une idée de scénario qui pourrait devenir le sujet d’un prochain article.
🛠️ Ma boîte à outil
On m’a souvent demandé de lister les outils que j’utilise au quotidien. Ils sont tous référencés dans ce Notion.

👁️ Présentation du scénario


✅ Quel est l’objectif du scénario ?
Faire exploser le nombre d'abonnés.
Pour y parvenir, j’ai testé plusieurs approches sur LinkedIn pour maximiser la visibilité de ma newsletter et inciter à l’abonnement :
Publier du contenu : c’est la base, mais indispensable pour poser les fondations.
Cibler les bons profils : responsables marketing, CEO, et autres rôles pertinents selon les scénarios.
Cibler selon les actions : la méthode la plus efficace ⭐.
Sur LinkedIn, l’automatisation est tendance, et de nombreux experts émergent. Mais le bon marketing reste une formule simple :
Le bon message. À la bonne personne. Au bon moment.
Décryptons mon automatisation :
La bonne personne : un profil LinkedIn qui commente une publication sur l’automatisation.
Le bon message :

Le bon moment : immédiatement après le commentaire, quand l’intérêt est encore vif.
C’est presque comme si les créateurs de contenu travaillaient pour moi.
Plus ils publient et génèrent des interactions sur l’automatisation, plus cela alimente mon fichier de prospection : un flux continu de profils qualifiés à qui présenter ma newsletter.
Et le meilleur dans tout ça ?
Le scénario tourne en automatique. Aucun suivi manuel, aucune intervention.
Chaque nouvelle publication ou interaction est une opportunité qui se déclenche sans effort de ma part.
⚙️ Comment fonctionne ce scénario ?
Identification des créateurs de contenu : repérer les profils influents qui publient sur l’automatisation.
Surveillance régulière de leur activité LinkedIn : suivre automatiquement leurs nouvelles publications.
Extraction des commentateurs : récupérer tous les profils qui interagissent avec leurs posts.
Dédoublonnage des profils : une étape très importante pour éviter de contacter la même personne plusieurs fois
Ajout à une campagne de prospection : alimenter une liste de prospects qualifiés.
Envoi d’un message personnalisé : un message qui se démarque des approches classiques de prospection pour capter l’attention.
Tout est automatisé, de l’identification à la prise de contact. 🚀
🛠️ Quelles applications sont nécessaires à ce scénario ?
Outil central pour extraire l’activité des créateurs de contenu et isoler les profils ayant commenté.
J’en profite, Phantombuster vient de sortir son offre Black Friday permettant d’économiser 40% sur le plan annuel. Si t’es un lecteur assidu de cette newsletter, tu sais que c’est un outil que je recommande vivement. Il te sera toujours utile tellement il est complet.

Il me permet d’envoyer les messages sur LinkedIn même si en soit, PhantomBuster pourrait le faire également.
💰 Quel est le coût estimé du scénario ?
Compte Make : pour orchestrer et automatiser les différentes étapes du processus. Avec mon lien affilié, tu auras 1 mois gratuit
Compte PhantomBuster : pour l’extraction des données LinkedIn. Avec l’offre Black Friday, tu payes 42€/mois.
Compte lemlist : pour l’envoi des messages personnalisés. Ils ont également une offre Black Friday offrant 30% de réduction. Cela fait $55/mois.
Ces outils combinés offrent une solution puissante pour automatiser efficacement votre prospection sur LinkedIn.
📊 Les résultats
Voici les performances obtenues après 12 jours, sur une base de 665 prospects :
260 profils contactés : dans le respect des limitations LinkedIn.
72% d’acceptations d’invitation : soit 189 nouvelles connexions.
16% d’interactions avec le message : ces échanges aboutissent souvent à des abonnements.
3 nouveaux abonnés par jour en moyenne depuis la mise en place.
Taux de conversion global : 13% (prise de contact → abonnement).
Un scénario efficace et mesurable, qui transforme LinkedIn en un canal puissant pour développer cette newsletter.
L’autre effet positif et moins visible : j’ajoute des personnes qualifiées dans mon réseau. Ces personnes auront la possibilité de convertir plus tard et augmenter le reach de mes futurs publications. 🚀
🧑🏫 Etapes pour créer ce scénario
Etape 1 : Définir les créateurs à suivre
Création du trigger :
J’utilise le module “Tools - Set multiple variables” pour définir les informations des créateurs de contenu à suivre.Paramètres à configurer :
URL LinkedIn : l’URL du profil LinkedIn du créateur dans le même segment que toi.
Name : le prénom et le nom du créateur.
Gestion de plusieurs créateurs :
Pour suivre plusieurs profils, ajoute des variables supplémentaires :
URL LinkedIn 2 / Name 2
URL LinkedIn 3 / Name 3
Structure du scénario :
Chaque créateur dispose d’une branche dédiée dans le scénario. Avec 3 créateurs suivis, mon automatisation s’étend sur 3 branches indépendantes, chacune optimisée pour un profil spécifique.

Déclenchement et répartition des branches
Pour éviter de surcharger les créateurs en scrappant quotidiennement, j’ai réparti les déclenchements sur une semaine :
Lundi / Jeudi / Dimanche : Créateur 1
Mardi / Vendredi : Créateur 2
Mercredi / Samedi : Créateur 3
Voici le filtre à paramétrer pour le Lundi / Jeudi / Dimanche :
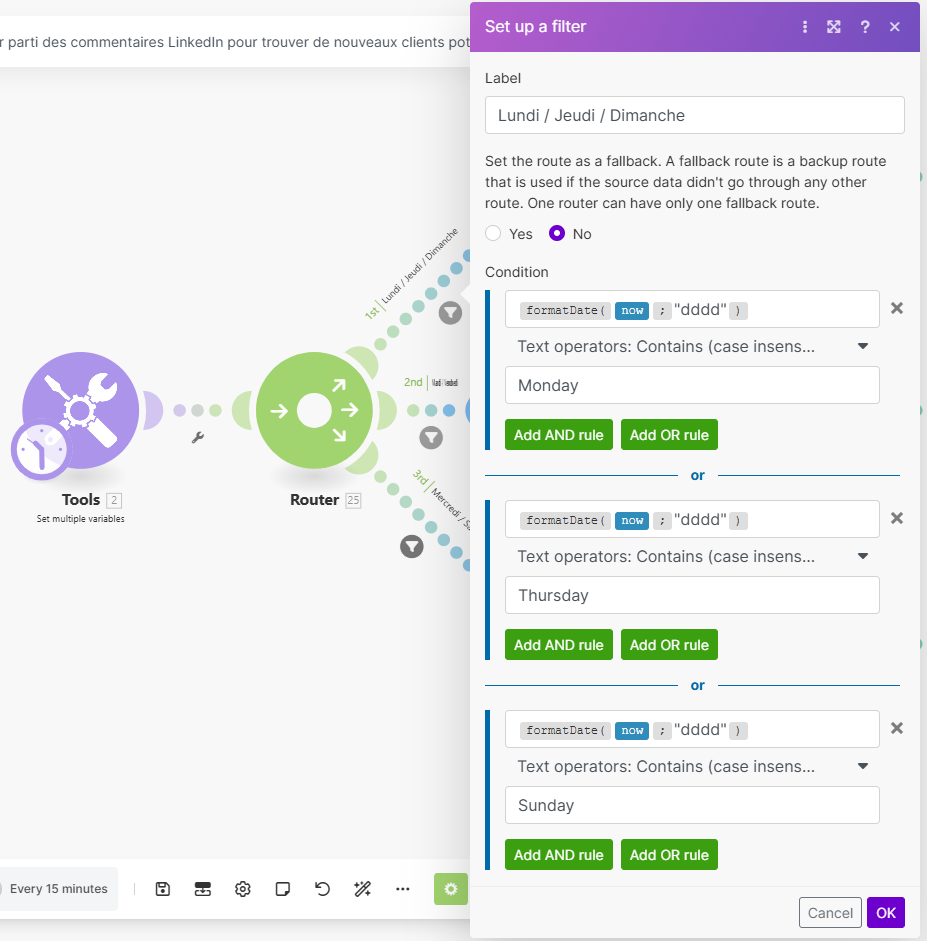
Cette configuration garantit que chaque créateur est suivi au bon moment, laissant un délai raisonnable pour qu’ils publient de nouveaux contenus.
Etape 2 : Appel API à PhantomBuster (déjà présent dans les derniers articles)
Le module "PhantomBuster - Launch a Phantom" présente actuellement un bug qui empêche son fonctionnement correct. Lors de sa configuration, une erreur s'affiche, rendant impossible le lancement automatique des Phantoms via ce module.

Solution alternative :
En attendant la résolution du problème, vous pouvez utiliser le module "HTTP - Make a request" pour interagir directement avec l'API de PhantomBuster. Cette méthode permet de lancer vos Phantoms sans passer par le module défectueux.
Pour commencer, on va sur son compte PhantomBuster et on paramètre ce Phantom 👇

Ce module nous permet de scraper les derniers posts de notre créateur préféré sur LinkedIn.
Pas besoin de se prendre la tête avec le paramétrage : on active le Phantom, et on organise les requêtes grâce à l’API suivante.
Pour cela, retournez dans votre scénario Make et ajoutez le module “HTTP - Make a request”.
Je vais te partager mon paramétrage mais je te conseille de consulter cette page : Documentation PhantomBuster
Elle est très claire et utile si vous souhaitez ajuster ou personnaliser votre scénario.
Voici comment remplir le module de requête HTTP

URL : C’est l’URL de l’API Phantom pour déclencher un scénario.
POST : On envoi une requête
Content-Type : application/json car on envoi la requête en JSON
X-Phantombuster-Key : Je te laisse ajouter ta clé API PhantomBuster (j’ai effacé quelques caractères du screen 🤓)
C’était la partie simple, maintenant voici la partie plus complexe :

{
"argument": "{
\"numberOfLinesPerLaunch\": 1,
\"numberMaxOfPosts\": 7,
\"csvName\": \"result\",
\"activitiesToScrape\": [
\"Post\"
],
\"spreadsheetUrl\": \"Notre Variable URL LinkedIN\",
\"userAgent\": \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36\",
\"sessionCookie\": \"Ton_cookie_linkedin\"
}",
"id": "2495260618152888"
}
Cela peut paraître complexe, mais décomposons pour mieux comprendre :
"argument" : ce sont les instructions données au Phantom, autrement dit ce que tu veux qu’il scrappe.
numberOfLinesPerLaunch : Nombre de profils à scrapper par lancement → Ici, 1.
numberMaxOfPosts : Nombre maximum de posts à récupérer → J’ai 20 dans mon screen mais au vu de la fréquence je pense que 7 est bien suffisant.
csvName : Nom du fichier CSV généré → "result" (peu crucial).
activitiesToScrape : Type de données à récupérer → Ici, les "Posts".
spreadsheetUrl : L’URL LinkedIn du profil à scrapper → Réfère toi à la variable définie dans le premier module.
userAgent : L’identifiant du navigateur utilisé pour le scraping.
sessionCookie : Je te laisse mettre ton cookie LinkedIn ici. Ce lien t’explique comment le retrouver.
Enfin, en dehors de l’argument :
id : L’identifiant de votre Phantom → Rendez-vous sur l’interface de PhantomBuster, dans l’URL du Phantom, copiez les chiffres entre
/phantoms/et/console/.
Etape 3 : Ajout à un Google Sheets
Pour centraliser les données, voici comment j’ai structuré mon fichier Google Sheets intitulé Export Post LinkedIn - PhantomBuster :
Organisation des feuilles permanentes :
Feuille 1 : Nom du créateur 1
Feuille 2 : Comments Nom du créateur 1
Feuille 3 : Nom du créateur 2
Feuille 4 : Comments Nom du créateur 2
Feuille 5 : Nom du créateur 3
Feuille 6 : Comments Nom du créateur 3
Ces 6 feuilles servent à :
Conserver un historique des posts/commentaires scrappés.
Éviter les doublons lors des prochaines exécutions.
Utilisation de feuilles temporaires :
Pour chaque exécution du scénario :
Créer une nouvelle feuille temporaire via le module Google Sheets - Add a Sheet.
Cette feuille temporaire :
Stocke les nouveaux posts/commentaires scrappés.
Permet de comparer ces données avec les feuilles permanentes pour détecter et supprimer les doublons.
Une fois la comparaison effectuée et les doublons supprimés, les nouveaux posts/commentaires sont ajoutés aux feuilles permanentes.
Pourquoi utiliser des feuilles temporaires ?
Cela simplifie le processus de dédoublonnage, en isolant uniquement les nouvelles données récupérées lors de chaque exécution.
On ajoute donc à la suite du module HTTP un module “Google Sheets - Add a Sheet”. Cette feuille sera temporaire, le temps de stocker les nouveaux posts scrapper et les comparer aux posts déjà scrappés afin de dédoublonner.

⚠️ Important de mettre cette nouvelle feuille en Index 0.
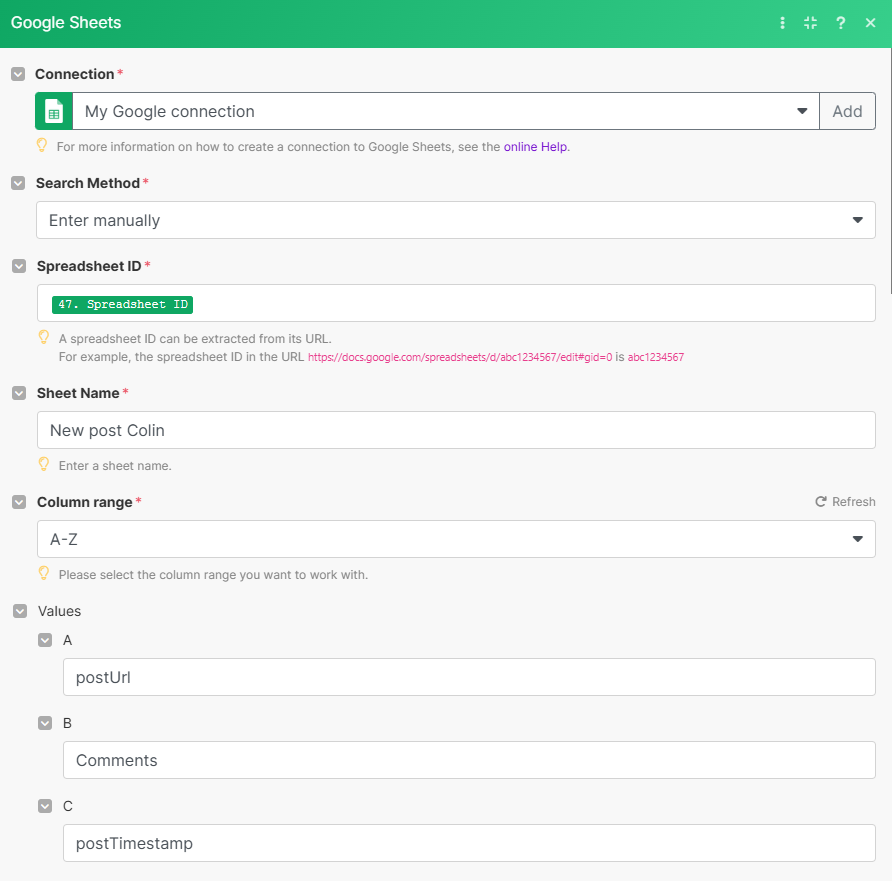
Pour que PhantomBuster utilise correctement la nouvelle feuille temporaire comme source, il est crucial de la placer en première position dans le fichier Google Sheets. En effet, PhantomBuster utilise toujours la feuille située à l’Index 0.Maintenant que c’est fait, on ajoute un autre module “Google Sheets - Add a Row”
Il est utile pour renseigner un header à notre nouvelle feuille :
Etape 4 : Récupération des résultats PhantomBuster

Module 1 : Text Parser - Match Pattern
Ce module sert à isoler le container ID renvoyé par le module HTTP - Make a Request. Le container ID est une information essentielle pour identifier les données récupérées par PhantomBuster.

Module 2 : Sleep
Afin de laisser le temps à notre Phantom de scrapper les posts, nous allons mettre en pause le scénario pendant 90 secondes.

Module 3 : “PhantomBuster - Download a Result”
Maintenant qu’on a isolé le container ID et qu’on a laissé le Phantom travailler on récupère le résultat

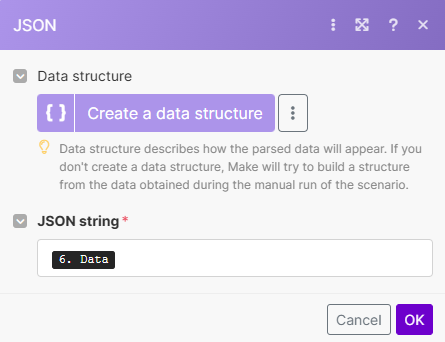
Modules 4 & 5 : “JSON - Parse JSON”
Deux modules Parse JSON sont nécessaires pour récupérer les informations du Phantom et les rendre exploitables par la suite.
Premier module :
Récupère la data brute renvoyée par le module PhantomBuster.
Source d’entrée : utilisez la réponse JSON du module précédent (via le container ID).
Deuxième module :
Reprend les données structurées du premier module pour les convertir dans un format exploitable pour les étapes suivantes.

Voici le résultat d’un output. Ce qui va nous intéresser, c’est de récupérer le lien de la publication.

Etape 5 : Ajout à notre feuille temporaire
Dans cette étape, on va ajouter l’ensemble des posts scrappés sur notre feuille temporaire. Pour cela on ajoute le module “Google Sheets - Add a Row”

Vu que le JSON final contient plusieurs bundles (autant que le nombre de publications scrappées), chaque module suivant Parse JSON va se déclencher plusieurs fois.
C’est parfait pour “Add a Row”, mais pas pour les étapes suivantes.
Pour éviter de consommer des opérations inutilement, on ajoute un module “Array Aggregator”.
Ce module regroupe tous les bundles en un seul tableau, ce qui simplifie les traitements globaux pour la suite.

Voici le paramétrage du module Array aggregator

Etape 6 : Dédoublonnage
Pour dédoublonner cela va être assez simple, on va :
lister les URL des publications de notre nouvelle feuille
lister les URL des publications de notre feuille permanentes
Comparer les résultats et dès que deux urls sont identiques, on supprime la ligne de la feuille temporaire.

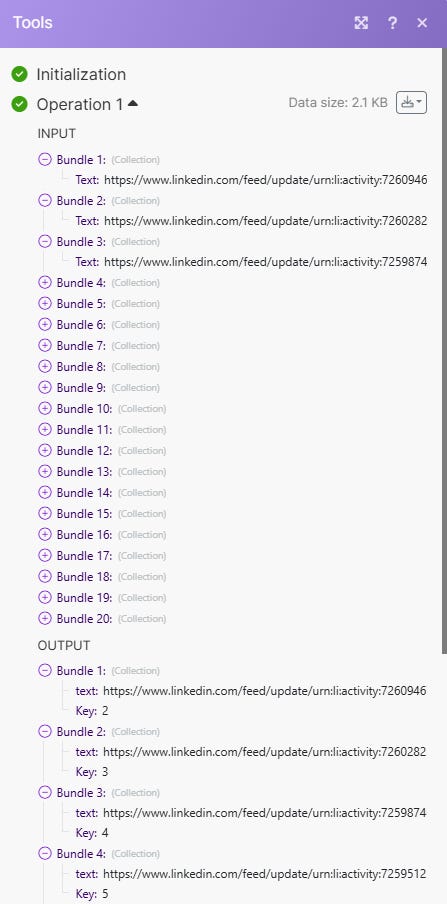
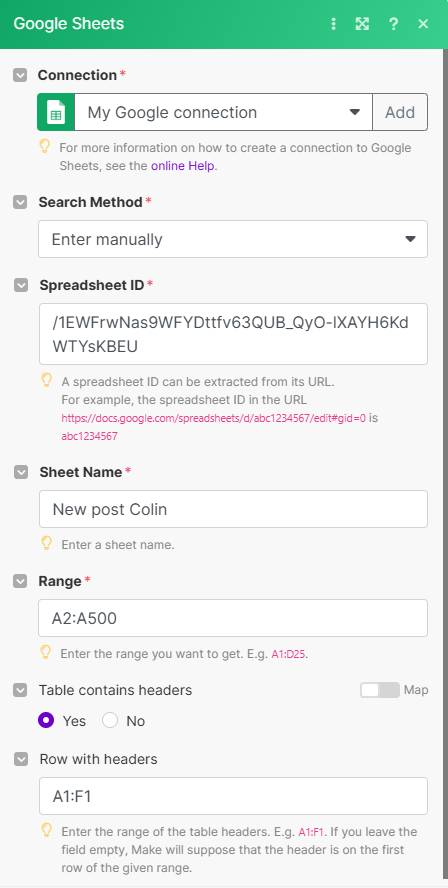
Concrètement on va ajouter un module “Google Sheets - Get Range Values” sur la feuille “Nom créateur 1”. Ce module va nous permettre de lister l’ensemble de la colonne A et retourner les valeurs
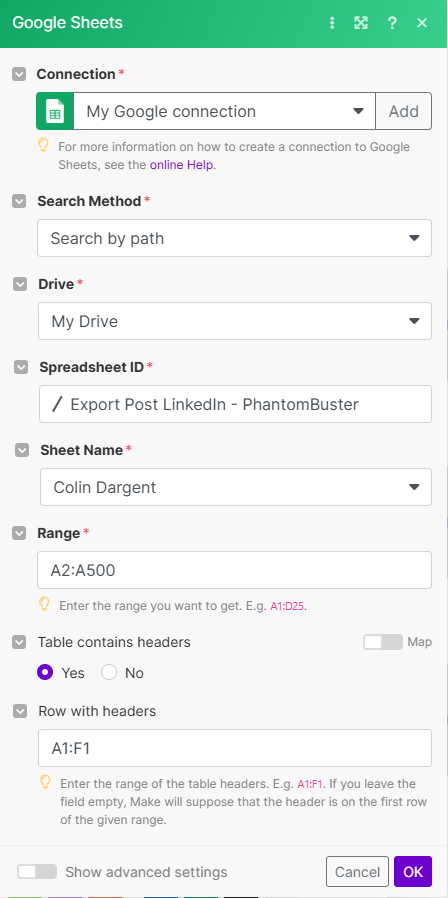
💡 Mettre de la range A2:A500 permet de ne pas récupérer le header et se concentrer sur les valeurs.Voici un exemple d’Output :

Afin de se concentrer uniquement sur l’URL de la publication, on ajoute le module “Tools - Text aggregator”

Ce qui permettra d’avoir un Output comme cela :
⚠️ Pour que tout fonctionne bien dès la première utilisation, il faut que tu ajoutes le lien d'une publication random dans ta feuille permanente.
Tu peux mettre le lien d'une de tes publications.
Cela permet d'avoir au moins une valeur retournée sinon le scénario ne fonctionne pas bien.
Tu pourras l'effacer après.Ensuite tu fais la même chose avec la feuille temporaire
Google Sheets - Get Range Values
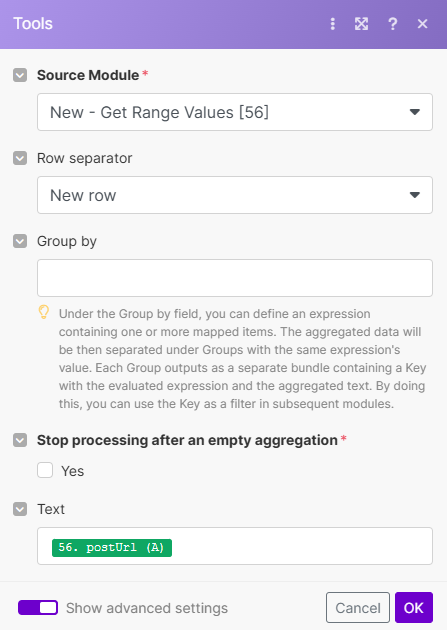
Tools - Text aggregator : cette fois-ci tu ne les regroupent pas par Row Number.
Etape 7 : Suppression des doublons
Maintenant qu’on a lister l’ensemble des URL des deux Sheets, il reste plus qu’à supprimer les doublons.
Pour cela on ajoute un ajoute le module “Google Sheets - Search Rows”
On va ajouter un filtre entre notre dernier Text aggregator et notre Search Rows :

Notre filtre va laisser passer toutes les URLs présentes dans les deux Sheets.
Il nous restera plus qu’à isoler la ligne avec le module Search Rows :

Ce module va nous retourner toutes les lignes présentant un doublon.
On fini par le module “Google Sheets - Delete a Row”. Ce module va supprimer toutes les lignes que le module précédent a identifié.

Maintenant que ta branche est finie, tu n’as plus qu’à dupliquer l’ensemble des modules pour te créer une nouvelle branche.
Il te suffira de modifier le maping et les noms de Sheets et tout se passera bien.
A la fin de ce premier scénario, tu possèdes la liste dédoublonnée de tous les posts de ton (ou tes) créateur.
Dans quelques jours je te montre comment faire la même chose pour les commentaires.
Ah et j’oubliais, à la fin il faut que tu ajoutes le module “Scenarios - Run a Scenario”. Ce module déclenche un autre scénario Make.com, parfait pour lier plusieurs scénarios entre eux.

🏁 Félicitations la première étape est finie ! 🏁
Rendez-vous dans les prochains jours pour clôturer cette automatisation.
N’hésite pas à me faire tes retours en commentaire sur ce scénario.
➡️ Tu préfères un format vidéo pour expliquer le scénario ?
➡️ Tu as des critiques constructives à faire ?
Bravo pour ce tuto ! Ca me donne envie de le faire pour ma propre Newsletter et page LinkedIn associée.
Seulement, mon envie est juste de partager, pas particulièrement de monétiser, et ça fait un peu mal de payer des outils juste pour être utile à plus de monde :D