



#23.2 : Comment j'ai réussi à gagner des abonnés de manière automatisée ? (Part 2)
L'automatisation LinkedIn qui fait grandir votre audience, sans effort.


Introduction
Bonjour à tous 👋
Cet article fait suite au dernier scénario que j’ai posté :

J’ai récemment mis en place ce scénario pour un entrepreneur possédant une Newsletter.
J’en ai profité pour optimiser chaque étape, j’ai réalisé qu’au lieu de tout réécrire ici, ce serait l’occasion parfaite de lancer une chaîne YouTube pour expliquer cette automatisation en détail.
🙏 Envie de me soutenir ?
Crée un compte Make avec ce lien affilié (tu auras 1 mois gratuit)
Prends rendez-vous avec moi pour discuter automatisation
Propose une idée de scénario qui pourrait devenir le sujet d’un prochain article.
🛠️ Ma boîte à outil
On m’a souvent demandé de lister les outils que j’utilise au quotidien. Ils sont tous référencés dans ce Notion.
Nouveauté : Topaz Labs, découvert et testé récemment !

👁️ Présentation du scénario



✅ Quel est l’objectif du scénario ?
J’ai testé plusieurs approches sur LinkedIn pour maximiser la visibilité et les abonnements à ma newsletter :
Publier du contenu : la base, mais incontournable.
Cibler les bons profils : responsables marketing, CEOs, et rôles pertinents.
Cibler selon le comportement de ta cible : la méthode la plus puissante ⭐.
Mon automatisation en action :
La bonne personne : un profil qui commente une publication sur l’automatisation.
Le bon message : un pitch personnalisé qui capte l’intérêt.
Le bon moment : juste après leur commentaire, quand l’intérêt est encore frais.
Résultat ?
Chaque interaction sur LinkedIn devient une opportunité.
Les créateurs de contenu contribuent à me constituer un vivier de prospection : leurs publications attirent les bons profils, qui alimentent mon fichier en continu.
Le meilleur dans tout ça ? C’est 100% automatisé. Aucune intervention, aucun suivi manuel. Chaque commentaire déclenche une action.
Un flux constant de prospects qualifiés, sans effort supplémentaire.
⚙️ Comment fonctionne ce scénario en Partie 2 ?
Récupération des commentaires : Basée sur les publications scrapées en partie 1.
Filtrage : Exclure les personnes déjà contactées, le créateur de contenu et les profils déjà dans notre réseau.
Nettoyage : Suppression des Sheets temporaires pour garder le processus propre.
Inscription à la campagne : Les profils qualifiés sont automatiquement ajoutés.
Point clé :
L’étape de filtrage est la plus complexe et nécessite le plus de modules dans le scénario.
🛠️ Quelles applications sont nécessaires à ce scénario ?
Pour extraire l’activité des créateurs, isoler les profils ayant commenté et automatiser la prise de contact, PhantomBuster s’est révélé plus efficace que lemlist, que j’évoquais en partie 1.
Après tests, PhantomBuster s’adapte mieux à ce type de workflow, rendant l’extraction et la qualification des profils plus fluides.
L’outil est capable de faire l’ensemble des étapes.
💰 Quel est le coût estimé du scénario ?
Compte Make : pour orchestrer et automatiser les différentes étapes du processus. Avec mon lien affilié, tu auras 1 mois gratuit
Compte PhantomBuster : Il te faut minimum le compte “Starter” car l’automatisation va te prendre 4 slots de Phantom. C’est donc 56€ / mois.
Ces outils combinés offrent une solution puissante pour automatiser efficacement ta prospection sur LinkedIn.
📊 Les résultats
Voici les performances obtenues après 12 jours, sur une base de 665 prospects :
658 profils contactés : dans le respect des limitations LinkedIn.
77% d’acceptations d’invitation : soit 504 nouvelles connexions.
24% d’interactions avec le message : ces échanges aboutissent souvent à des abonnements.
3 nouveaux abonnés par jour en moyenne depuis la mise en place.
Taux de conversion global : 13% (prise de contact → abonnement).
Ce workflow transforme LinkedIn en un levier incontournable pour développer ma newsletter.
Effets visibles :
Une croissance mesurable des abonnés qualifiés.
Un réseau enrichi de profils ciblés, prêts à convertir à terme et à amplifier la portée de mes publications. 🚀
Effets moins visibles, mais tout aussi précieux :
Les profils familiers avec l’automatisation sont impressionnés par la sophistication du scénario, renforçant mon autorité sur le sujet.
Un double impact qui combine acquisition immédiate et influence durable.
🧑🏫 Etapes pour créer ce scénario
Etape 1 : Définir les créateurs à suivre
Création du trigger :
J’utilise le module “Tools - Set multiple variables” pour définir les informations des créateurs de contenu à suivre.Paramètres à configurer :
URL LinkedIn : l’URL du profil LinkedIn du créateur dans le même segment que toi.
Name : le prénom et le nom du créateur.
Gestion de plusieurs créateurs :
Pour suivre plusieurs profils, ajoute des variables supplémentaires :
URL LinkedIn 2 / Name 2
URL LinkedIn 3 / Name 3
Structure du scénario :
Comme dans la partie 1, chaque créateur dispose d’une branche dédiée dans le scénario. Avec 3 créateurs suivis, mon automatisation s’étend sur 3 branches indépendantes, chacune optimisée pour un profil spécifique.

Optimisation clé pour la maintenance
Nouvelle approche depuis la Partie 1 : créer un module dédié pour centraliser la mise à jour du cookie LinkedIn et du Browser Agent, deux paramètres essentiels pour PhantomBuster.
Pourquoi ?
Si LinkedIn modifie ton cookie de connexion, il suffit de l’actualiser dans un seul module au lieu des 3 modules d’appel API à PhantomBuster.
Gain de temps et maintenance simplifiée pour garder le scénario fonctionnel sans effort.
Une petite amélioration qui fait toute la différence en termes de gestion et d’efficacité.

Déclenchement et répartition des branches
Pour éviter de surcharger les créateurs en scrappant quotidiennement, j’ai réparti les déclenchements sur une semaine :
Lundi / Jeudi / Dimanche : Créateur 1
Mardi / Vendredi : Créateur 2
Mercredi / Samedi : Créateur 3
Voici le filtre à paramétrer pour le Lundi / Jeudi / Dimanche :
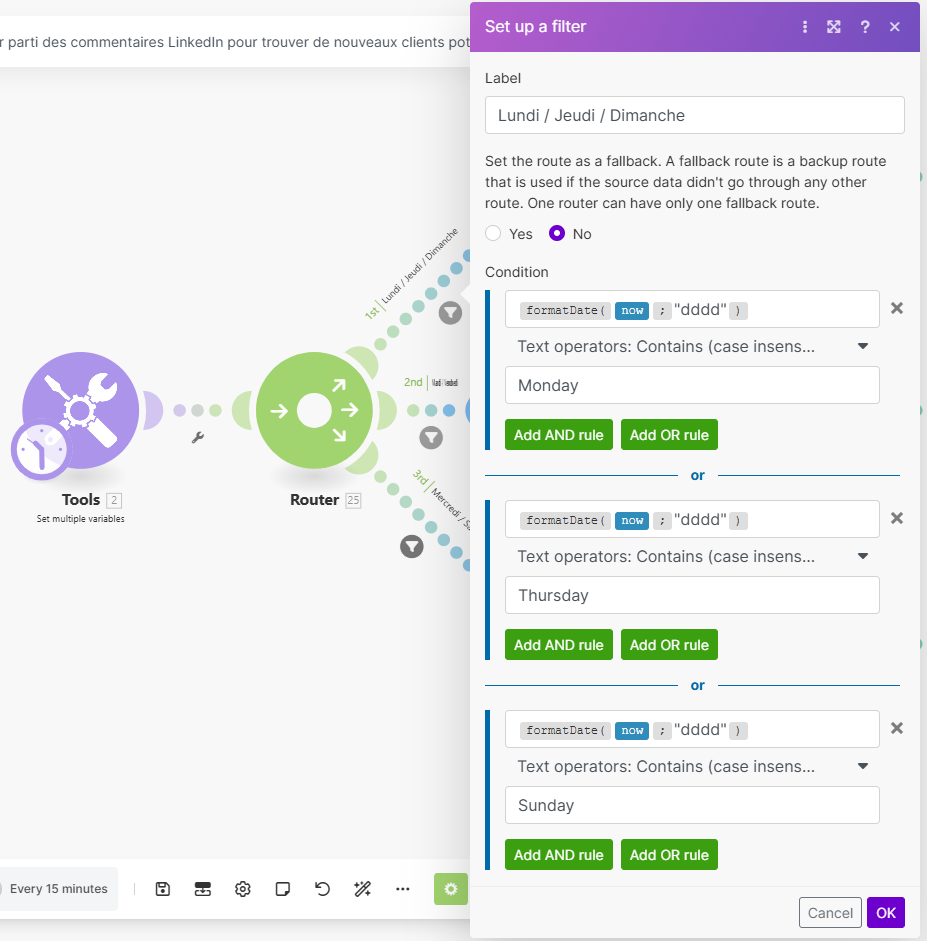
Le scénario se déclenche une fois par jour, en fonction du jour ce sera la branche d’un créateur spécifique.
Etape 2 : Appel API à PhantomBuster (déjà présent dans les derniers articles)
Le module "PhantomBuster - Launch a Phantom" présente actuellement un bug qui empêche son fonctionnement correct. Lors de sa configuration, une erreur s'affiche, rendant impossible le lancement automatique des Phantoms via ce module.

Solution alternative :
En attendant la résolution du problème, vous pouvez utiliser le module "HTTP - Make a request" pour interagir directement avec l'API de PhantomBuster. Cette méthode permet de lancer vos Phantoms sans passer par le module défectueux.
Pour commencer, on va sur son compte PhantomBuster et on paramètre ce Phantom 👇

Ce module extrait les profils LinkedIn ayant commenté une publication.
Fonctionnement :
Fournissez l’URL des publications - récupérées en Partie 1.
Le Phantom retourne automatiquement la liste des profils ayant commenté.
Simplification :
Pas besoin de configurer manuellement PhantomBuster :
L’activation se fait avec le minimum de paramétrage.
Les ajustements nécessaires sont réalisés directement dans Make via un module API.
Configuration dans Make :
Ajoutez un module HTTP - Make a request.
Paramétrez-le avec les détails suivants (exemple fourni ci-dessous).
Référez-vous à la Documentation PhantomBuster pour personnaliser ou approfondir.
Un gain de temps, avec une flexibilité maximale pour ajuster le scénario selon vos besoins.
Voici comment remplir le module de requête HTTP

URL : C’est l’URL de l’API Phantom pour déclencher un scénario. La même qu’en Partie 1.
POST : On envoi une requête
Content-Type : application/json car on envoi la requête en JSON
X-Phantombuster-Key : Je te laisse ajouter ta clé API PhantomBuster (j’ai effacé quelques caractères du screen 🤓)
C’était la partie simple, maintenant voici la partie plus complexe :
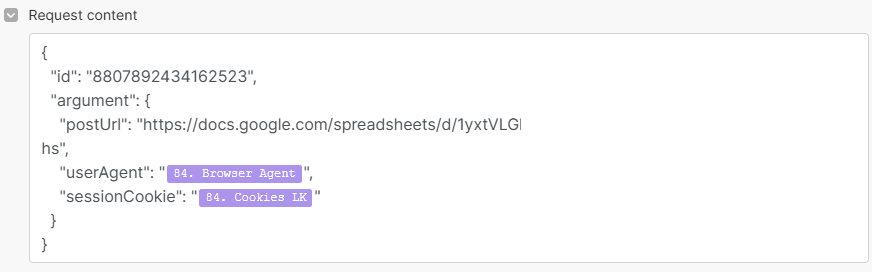
{
"id": "id de ton Phantom",
"argument": {
"postUrl": "URL de ton Google Sheets",
"userAgent": "{{84.`Browser Agent`}}",
"sessionCookie": "{{84.`Cookies LK`}}"
}
}
Pour le coup, il est plus simple que le JSON à fournir en partie 1.
id : L’identifiant de votre Phantom → Rende toi sur l’interface de PhantomBuster, dans l’URL du Phantom, copiez les chiffres entre
/phantoms/et/console/.
"argument" : ce sont les instructions données au Phantom, autrement dit ce que tu veux qu’il scrappe.
postUrl : C’est les URL de publication que tu donnes à ton Phantom.
Si tu en as qu’une, tu peux lui donner directement l’URL ici.
Si tu en as plusieurs comme dans ce scénario :
Tu les regroupes sur un Google Sheets
Tu mets les URL en première colonne
Et tu passes ton Google Sheets en public pour que le Phantom puisse y accéder

userAgent : L’identifiant du navigateur utilisé pour le scraping → Il est défini dans ton 2ème module
sessionCookie : Je te laisse mettre ton cookie LinkedIn ici. Ce lien t’explique comment le retrouver. → Pareil, si tu veux bien faire, tu l’as déjà renseigner dans le deuxième module.
Etape 3 : Ajout à un Google Sheets
C’est ici que j’ai fait le plus de changement : par rapport à l’organisation du Google Sheets. Je suis passé à 2 Sheets permanentes et 2 Sheets temporaires.
Comparé aux 8 Sheets que j’avais au maximum dans la première partie.
J’ai centralisé l’ensemble des posts scrapés sur une feuille et les personnes ayant commentées sur une autre. Voici ce que ça donne :

Pour rappel, les Sheets permanentes servent à :
Conserver un historique des posts/commentaires scrappés.
Éviter les doublons lors des prochaines exécutions.
Utilisation de feuilles temporaires :
Pour chaque exécution du scénario :
Créer une nouvelle feuille temporaire via le module Google Sheets - Add a Sheet.
Cette feuille temporaire :
Stocke les nouveaux posts/commentaires scrappés.
Permet de comparer ces données avec les feuilles permanentes pour détecter et supprimer les doublons.
Une fois la comparaison effectuée et les doublons supprimés, les nouveaux posts/commentaires sont ajoutés aux feuilles permanentes.
Pourquoi utiliser des feuilles temporaires ?
Cela simplifie le processus de dédoublonnage, en isolant uniquement les nouvelles données récupérées lors de chaque exécution.
On ajoute donc à la suite du module HTTP un module “Google Sheets - Add a Sheet”. Cette feuille sera temporaire, le temps de stocker les nouveaux posts scrapper et les comparer aux posts déjà scrappés afin de dédoublonner.

Maintenant que c’est fait, on ajoute un autre module “Google Sheets - Add a Row”
Il est utile pour renseigner un header à notre nouvelle feuille :

Colonne A : l’URL du profil LinkedIn de la personne ayant commenté
Colonne B : Son prénom
Colonne C : l’URL de la publication LinkedIn à l’origine du commentaire
Colonne D : Le nom du créateur
Colonne E : Degree : si la personne est dans votre 1er, 2ème ou 3ème cercle de relation
Colonne F : Date
Colonne G : Message
Etape 4 : Récupération des résultats PhantomBuster

Module 1 : Text Parser - Match Pattern
Ce module sert à isoler le container ID renvoyé par le module HTTP - Make a Request. Le container ID est une information essentielle pour identifier les données récupérées par PhantomBuster.

Module 2 : Sleep
Afin de laisser le temps à notre Phantom de scrapper les commentaires, nous allons mettre en pause le scénario pendant 200 secondes.

Module 3 : “PhantomBuster - Download a Result”
Maintenant qu’on a isolé le container ID et qu’on a laissé le Phantom tourner on récupère le résultat !

Modules 4 & 5 : “JSON - Parse JSON”
Deux modules Parse JSON sont nécessaires pour récupérer les informations du Phantom et les rendre exploitables par la suite.
Premier module :
Récupère la data brute fournie par le module PhantomBuster.
On map le champ Data issu de PhantomBuster

Deuxième module :
On prend le résultat du premier module JSON pour le parser une deuxième fois. Cette étape est cruciale pour avoir de la donnée exploitable dans les prochains modules.

Voici le résultat d’un output final. Ce qui va nous intéresser, c’est la récupération de l’URL du profil et le prénom. On peut également imaginer faire des actions en fonction du commentaire mais on va essayer de ne pas trop complexifier ce scénario 😅

Etape 5 : Ajout des personnes à notre Google Sheets
Une fois que nous avons un beau JSON contenant tous les profils à ajouter à notre Google Sheets, il ne reste plus qu’à passer à l’action.
Filtre
J’ai ajouté un filtre avant le prochain module (Array Aggregator). Il garde seulement les profils en 2e et 3e cercle et exclut le créateur du post (qui commente toujours ses publications).
Résultat : un Google Sheets plus pertinent.

Les deux prochains modules sont liés. T’as besoin des deux modules présents dans le scénario pour aller au bout du paramétrage.
Module 1 : Array Aggregator
Ce module te permet d’économiser beaucoup d’opérations sur Make. Le module Parse JSON va créer un bundle pour chaque profil LinkedIn trouvé.
Prenons un exemple concret : disons que tu scrap 1 000 profils d’un coup, l’ensemble des modules suivants va être déclencher 1 000 fois. Il reste encore 17 modules, c’est potentiellement 17 000 opérations. Donc on va éviter.
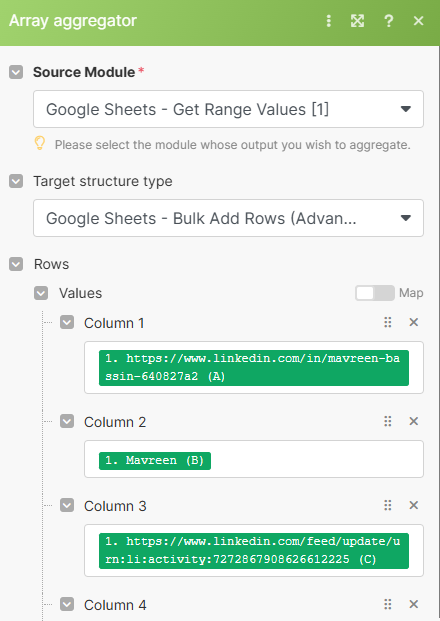
L'array aggregator va transformer les 1 000 bundles en 1 seul avec toutes les données.Voici le paramétrage :

Source Module : On connecte le dernier module Parse JSON
Target structure type : On sélectionne le prochain module “Google Sheets - Bulk Add Rows”. C’est pour cela que je te disais qu’on avait besoin des deux modules créés pour aller au bout du paramétrage.
Ensuite on map les champs de notre Google Sheets avec les bonnes propriétés extraites de PhantomBuster.
En dernière colonne j’ai également mappé l’ID du Sheet temporaire qu’on vient de créer. Ce sera utile pour supprimer le Sheet dans les dernières étapes.

Module 2 : Google Sheets - Bulk Add Rows
Ce module optimise aussi vos opérations. Contrairement à "Google Sheets - Add a row" qui s’exécute pour chaque profil, celui-ci ajoute tous les profils en une seule fois grâce à une Array. Et ça tombe bien, on l’a déjà générée avec le module précédent.

Etape 6 : Dédoublonnage
Etape similaire au scénario de la Partie 1.
Pour dédoublonner, voici le process :
Lister les URLs des profils LinkedIn de la nouvelle feuille.
Lister celles de la feuille permanente.
Comparer les deux listes : si une URL est identique, supprimer la ligne correspondante dans la feuille temporaire.

Concrètement on va ajouter un module “Google Sheets - Get Range Values” pour la feuille “Comments Scrap”. Ce module va nous permettre de lister l’ensemble de la colonne A (URL LinkedIn) et retourner les valeurs
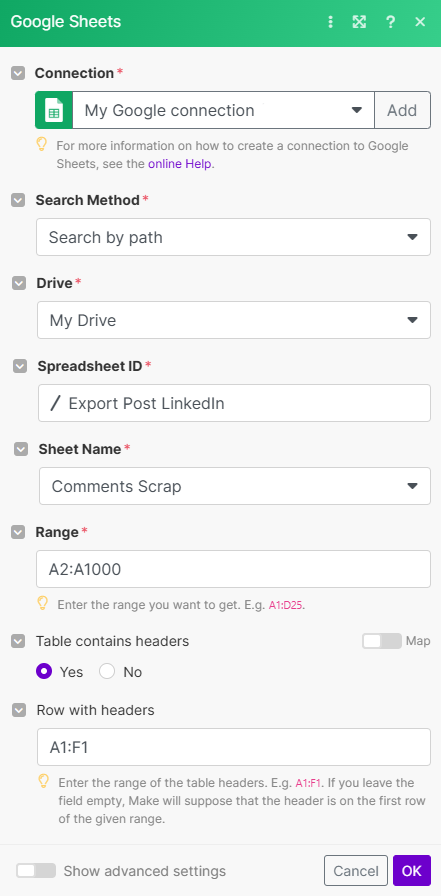
💡 Mettre de la range A2:A500 permet de ne pas récupérer le header et se concentrer sur les valeurs.Voici un exemple d’Output :

Afin de se concentrer uniquement sur l’URL des profils, on ajoute le module “Tools - Text aggregator”

⚠️ Pour que tout fonctionne bien dès la première utilisation, il faut que tu ajoutes le lien d'un profil LinkedIn random dans ta feuille permanente.
Tu peux mettre ton propre profil.
Cela permet d'avoir au moins une valeur retournée sinon le scénario ne fonctionne pas bien.
Tu pourras l'effacer après.Ensuite tu fais la même chose avec la feuille temporaire
Google Sheets - Get Range Values

Tools - Text aggregator : cette fois-ci tu ne les regroupent pas par Row Number.

Etape 7 : Suppression des doublons
Maintenant qu’on a lister l’ensemble des URL des deux Sheets, il reste plus qu’à supprimer les doublons.
Pour cela on ajoute un ajoute le module “Google Sheets - Search Rows”
On va ajouter un filtre entre notre dernier Text aggregator et notre Search Rows :

Notre filtre va laisser passer toutes les URLs présentes dans les deux Sheets.
Il nous restera plus qu’à isoler la ligne avec le module Search Rows :

Ce module va nous retourner toutes les lignes présentant un doublon.
🤔 Malheureusement un nouveau petit challenge se met sur notre route !
Make présente les doublons par ordre croissant (5 → 12 → 18). Si on supprime la ligne 5, la ligne 12 devient 11, faussant l’ordre.
Solution : supprimer les doublons par ordre décroissant (18 → 12 → 5) pour préserver l’intégrité des lignes.Etape 8 : Inverser l’ordre des lignes en doublon
Première étape c’est d’ajouter un module Array Aggregator afin de centraliser toutes les lignes dans une seule et même Array. Comme ici où nous avons deux doublons
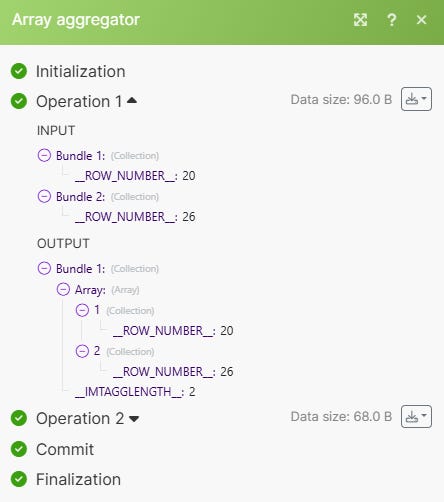
Voici le paramétrage :

Ensuite on transforme l’Array en JSON grâce au module “JSON - Transform to JSON”
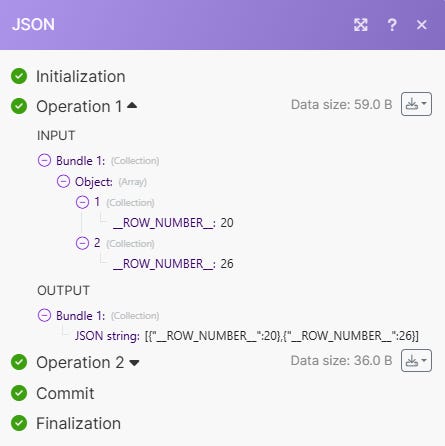
Je dois avouer avoir eu recours à la facilité via le module OpenAI pour qu’il détecte l’ordre des lignes et les inverse. Voici mes prompts :
System
You're a helpful and intelligent assistant.User 1 : Prompt
Your task is to identify a chain of number and return it under a JSON Format.
These number are row numbers, you need to give back to me the chain in a descending order.
Return your result in JSON using this format:
{
"array": [
{"number": "value goes here"}
]
}User 2 : Valeur test
[{"__ROW_NUMBER__":2},{"__ROW_NUMBER__":108},{"__ROW_NUMBER__":189},{"__ROW_NUMBER__":268},{"__ROW_NUMBER__":269},{"__ROW_NUMBER__":270}]Assistant : Résultat attendu
{
"array": [
{"number": 270},
{"number": 269},
{"number": 268},
{"number": 189},
{"number": 108},
{"number": 2}
]
}
User 3 : Valeur réelle
On map le JSON généré dans le dernier moduleVoici le résultat : On voit bien que le module a inversé l’ordre

On place le module “Iterator” à la suite afin de transformer l’Array en résultat exploitable.

L’Iterator renvoi deux bundle, le prochain module “Delete a Row” va s’exécuter deux fois.

Dernier défi à résoudre 😬
Même après comparaison avec le Sheet permanent, des doublons peuvent exister dans le Sheet temporaire lui-même. Il faut donc effectuer un second nettoyage, cette fois-ci entre les lignes, pour supprimer les doublons restants et garantir un fichier propre.
Etape 8 : Deuxième nettoyage

L’idée est similaire que l’étape précédente donc je vais aller vite :
Module 1 : On liste l’ensemble des URL de profil LinkedIn
Module 2 : On les regroupe en Array en agrégeant la colonne A
Filtre : On laisse passer uniquement les doublons, c’est à dire ceux qui ont un Array plus longue que 1
Module 3 : On transforme les Array en JSON
Module 4 : On inverse le sens des lignes avec OpenAI
Module 5 : On les transforme en bundle
Module 6 : On supprime les lignes en doublon
Tu ajoutes le module “Scenarios - Run a Scenario”. Ce module déclenche un autre scénario Make.com, parfait pour lier plusieurs scénarios entre eux.

Grâce à ce module, on va lancer le dernier scénario. Promis il est court !
Etape 9 : Suppression des Sheets temporaires

Dans ce scénario on va faire deux fois le même procédé :
Lister les publications du Sheets temporaire et les ajouter à notre Sheets permanent
Lister les profils LinkedIn du Sheets temporaire et les ajouter à notre Sheets permanent
C’est ce qu’il se passe au niveau des 6 premiers modules.
Le fonctionnement est le même comparé au scénario précédent :
Le “Get Range Values” permet de lister toutes les valeurs qu’on transforme en Array pour les ajouter à notre feuille permanente.
Ensuite pour supprimer les deux Sheets temporaire, nous allons avoir besoin de l’ID des deux Sheets.
Si t’as bien suivi l’étape 5, tu dois le retrouver dans ton Sheets temporaire :
En dernière colonne j’ai également mappé l’ID du Sheet temporaire qu’on vient de créer. Ce sera utile pour supprimer le Sheet dans les dernières étapes.On ajoute deux modules “Google Sheets - Get a Cell” permettant de récupérer l’ID qu’on a stocké dans la colonne D.
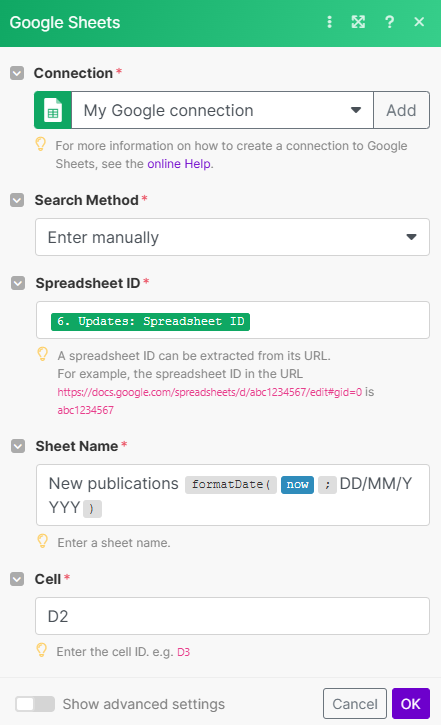
On se sert de la valeur retournée pour supprimer la feuille temporaire.

Notre travail sur Make est terminé, il ne reste plus qu’une étape. Paramétrer le Phantom permettant d’envoyer les demandes de relations + message de follow up une fois activée.
Etape 10 : Phantom LinkedIn Outreach
On sélectionne le Phantom “LinkedIn Outreach”, il prend deux slots.

Profiles to invite : On renseigne le Google Sheets.
Attention il faut bien mettre le Google Sheets en public pour que PhantomBuster puisse y accéder.Connect to LinkedIn : On renseigne le Cookie LinkedIn et le Browser Agent.
Invitation message : Je préfère ne pas en mettre
Follow-up messages : C’est le message qu’on envoi lorsque le prospect accepte l’invitation

Je recommande d’envoyer le plus tôt possible. Cela laisse moins de temps au prospect de t’écrire entre temps et casser ton automatisation.
Dans “Your Message”, je map avec mon champ “Message” du Google Sheets.
On a la possibilité d’ajouter un document et une image si besoin.
Behavior : Je suis resté classique avec 20 invitations par jour pendant les heures de travail de la semaine.
🏁 Félicitations le scénario est fini ! 🏁
Pour résumer !
Scénarios : engage et convertis efficacement
🎯 Identifie les personnes engagées sur ta niche.
➕ Ajoute-les à ton réseau.
💬 Envoie-leur un message différenciant qui valorise ton contenu ou service.
N’hésite pas à me faire tes retours en commentaire sur ce scénario.
➡️ Tu préfères un format vidéo pour expliquer le scénario ?
➡️ Tu as des critiques constructives à faire ?